常用开发工具
常用开发工具
在实际学习开发中,除了 Linux 方面的知识,经常需要修改系统配置文件和编辑代码。熟练使用编辑器工具可以帮助开发者提高开发速度和编程效率。本章节将介绍 Vim 和 Nano 编辑器,以及 GCC 等代码编译器。这些工具已经默认安装在 Core3566 上,用户可以直接使用。
1. Nano 编辑器
Nano 是一个简单易用的终端文本编辑器,适合初学者或对编辑器定制需求较少的开发者。它提供了基本的编辑功能,如插入、删除、复制和粘贴等,同时具有简单的界面和易于上手的操作方式。Nano 对于快速编辑或修复代码以及编辑配置文件等小型任务非常方便。虽然 Nano 的功能相对较简单,但由于其简洁性和易用性,它在某些场景下仍然是开发者的首选。
在终端启动输入 nano 即可启动 nano 编辑器或者你也可以在命令后面加上一个文件的路径来打开一个特定的文件。如果这个文件不存在,它就会被创建,例如,在树莓派终端输入 sudo nano luckfox.txt 打开后就可以像记事本一样编辑文档。
- 顶端这一行显示 nano 编辑器的版本和正在编辑的当前文件名。底部两行显示最常用的编辑器中的快捷键,^ 符号代表 Ctrl,M- 代表 Alt。
- 常用快捷键:
文件管理
Ctrl+S 保存
Ctrl+O 另存为
Ctrl+X 退出 nano
Ctrl+R 在当前缓存区插入文件
Ctrl+G 获取帮助编辑
Alt+N 打开关闭行号
Shift+ ↑ 或↓ 向上或向下选中
Alt + 3 对所选行或区域进行注释或取消注释
Alt + U 撤销
Alt + E 恢复搜素
Ctrl + Q 开始向后搜索
Ctrl + W 开始向前搜索
Alt + Q 向后搜索下一个匹配的文本
Alt + W 向前搜索下一个匹配的文本
2. Vim 编辑器
Vim 是一个高度可定制的文本编辑器,广泛用于开发人员在终端环境下进行编码工作。Vim 具有强大的编辑功能和广泛的插件生态系统,使得开发者可以高效地编辑和组织代码。Vim 支持多种编程语言,并提供了丰富的快捷键和命令,使得开发者能够快速导航、编辑和调试代码。由于其高度可定制性和强大的功能,Vim 在开发者中享有广泛的应用和高度的地位。以下只是简单地介绍一下它的用法和常用命令。
为了方面使用,一般在 Vim 配置文件后面添加下面三句:
set nu # 显示行号
syntax on # 语法高亮
set tabstop=4 #tab 退四格
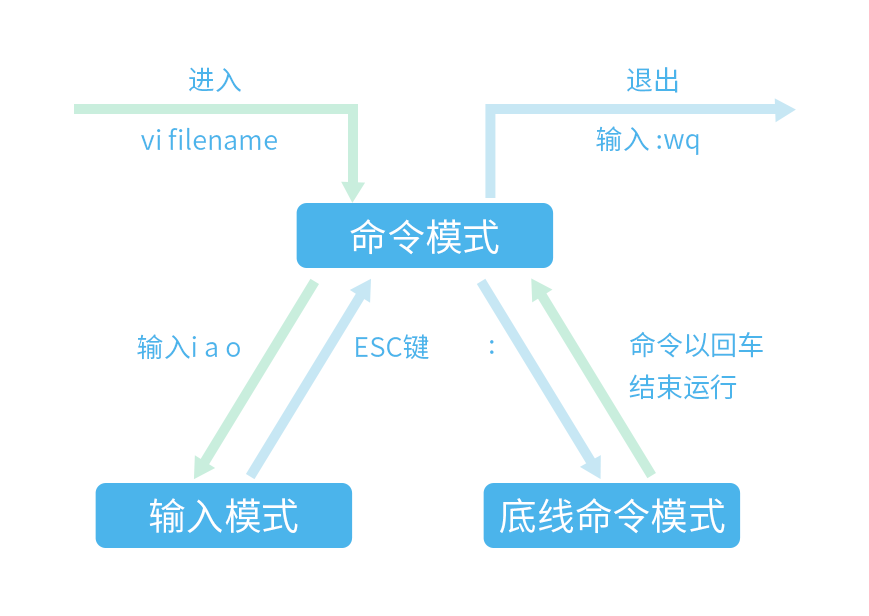
2.1 Vim 模式
基 本 上 Vim 共 分 为 三 种 模 式, 分 别 是 命 令 模 式(Command mode), 输 入 模 式(Insert mode)和底线命令模式(Last line mode):
- 命令模式:控制屏幕光标的移动,字符、字或行的删除,移动复制某区段。
- 输入模式:在此模式下输入字符,编辑文件。
- 底线模式:将文件保存或退出 Vim,也可以设置编辑环境,如寻找字符串、列出行号等。
我们可以将这三个模式想成底下的图标来表示:
2.2 常用命令
打开文件、保存、关闭文件(vi 命令模式下使用):
vim filename 打开 filename 文件 :w 保存文件 :q 退出编辑器,如果文件已修改请使用下面的命令 :q! 退出编辑器,且不保存 :wq 退出编辑器,且保存文件 :wq! 强制退出编辑器,且保存文件 ZZ 退出编辑器,且保存文件 ZQ 退出编辑器,且不保存 插入文本或行(vi 命令模式下使用,执行下面命令后将进入插入模式,按 ESC 键可退出插入模式):
a 在当前光标位置的右边添加文本 i 在当前光标位置的左边添加文本 A 在当前行的末尾位置添加文本 I 在当前行的开始处添加文本(非空字符的行首) O 在当前行的上面新建一行 o 在当前行的下面新建一行 R 替换(覆盖)当前光标位置及后面的若干文本 J 合并光标所在行及下一行为一行(依然在命令模式) 删除、恢复字符或行(vi 命令模式下使用):
x 删除当前字符 nx 删除从光标开始的 n 个字符 dd 删除当前行 ndd 向下删除当前行在内的 n 行 u 撤销上一步操作 U 撤销对当前行的所有操作 复制、粘贴(vi 命令模式下使用):
yy 将当前行复制到缓存区 nyy 将当前行向下 n 行复制到缓冲区 yw 复制从光标开始到词尾的字符 nyw 复制从光标开始的 n 个单词 y^ 复制从光标到行首的内容 y$ 复制从光标到行尾的内容 p 粘贴剪切板里的内容在光标后 P 粘贴剪切板里的内容在光标前
3. gcc 编译器
gcc 工具链中的三个核心组件是 gcc-core、Binutils和glibc。
- gcc-core:也称为 gcc 编译器,它是 gcc 工具链的核心,包括 C、C++、Fortran 等多种语言的编译器,可以将源代码编译成目标文件或可执行文件。
- Binutils:它是一个由GNU开发的二进制工具集,包括了汇编器(as)、链接器(ld)、目标文件格式转换工具(objcopy、objdump)、调试器(gdb)等工具,用于创建、修改、调试和分析可执行文件和目标文件。
- glibc:GNU C Library是 gcc 工具链中的C标准库,提供了基本的系统函数和 API,是 Linux 系统中用户空间程序开发的核心库。
- 这三个组件相互依赖,组成了一个完整的 gcc 工具链,使得开发者能够方便地进行软件开发和调试。在 Linux 系统中,这些组件通常是默认安装的,为开发者提供了一个高效的开发环境。在很多情况下会直接用 gcc 编译器来指代整套 gcc 编译工具链。
3.1 gcc 编译器
Linux系统下的 gcc 是一个开源编译器,全称为GNU Compiler Collection,由GNU工程开发。它支持多种编程语言,如C、C++、Objective-C、Fortran、Ada等,能够编译大型、复杂的应用程序。gcc 是一个可移植的编译器,支持多种硬件平台,如ARM、X86等。此外,gcc 不仅可以作为本地编译器使用,还可以进行跨平台交叉编译。可以使用如下命令查看:
gcc -v
3.1.1 gcc 编译步骤
Linux下 gcc 编译 C 文件为可执行文件分为四个步骤: 分别是 预编译、编译、汇编、链接。
预处理:在这个阶段,预处理器将对源代码进行处理,去掉注释、展开宏等,生成一个新的文件(通常以.i结尾)
- 将所有的 “#define” 删除,并展开所有的宏定义。
- 处理所有的条件预编译指令,比如:" #if #ifdef #elif #else #endif "。
- 处理所有的 “#include” 预编译指令。
- 删除所有的注释 “//” 、 “/* */”。
- 添加行号和文件名标识,以便编译时产生的行号信息以及用于编译错误或警告时能够显示行号。
- 保留所有的“#pragma”编译器指令。
编译:在这个阶段,编译器将对把预处理完的文件进行词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件(通常以.s结尾)。
汇编:在这个阶段,将汇编代码转换机器可以执行的二进制代码,生成的二进制代码文件通常以.o文件结尾。
链接:在链接过程中,链接器会解析函数、变量的引用关系,并将它们与其他目标文件中定义的函数、变量进行匹配,最终生成一个可执行的文件。
3.1.2 gcc 编译过程
gcc 使用的命令语法如下:
gcc [选项] 输入的文件名gcc 的选项有上百个,我们只介绍 gcc 的一些常见选项:
- 无选项:会在与源文件目录下产生a.out可执行文件。比如gcc test.c,将生成可执行文件a.out。
- -c:指定编译器只编译源文件,生成目标文件,不进行链接。
- -o:指定编译器生成的输出文件名,例如:gcc main.c -o myprogram。
- -Wall:开启所有警告,以便检测潜在的代码问题。
- -O:开启代码优化,以提高生成的代码效率。
- -g:生成调试信息,以便在程序运行时进行调试。
- -I:指定头文件的搜索路径,例如:gcc -I/usr/local/include myfile.c。
- -L:指定库文件的搜索路径,例如:gcc -L/usr/local/lib myfile.c。
- -l:链接指定的库文件,例如:gcc myfile.c -lm。
- -std:指定使用的C++标准,例如:gcc -std=c++11 myfile.cpp。
- -pthread:开启线程支持。
编译过程:
#直接编译成可执行文件
gcc test.c -o test
#以上命令等价于执行以下全部操作
#预处理,可理解为把头文件的代码汇总成C代码,把*.c转换得到*.i文件
gcc -E test.c -o test.i
#编译,可理解为把C代码转换为汇编代码,把*.i转换得到*.s文件
gcc -S test.i -o test.s
#汇编,可理解为把汇编代码转换为机器码,把*.s转换得到*.o,即目标文件
gcc -c test.s -o test.o
#链接,把不同文件之间的调用关系链接起来,把一个或多个*.o转换成最终的可执行文件
gcc test.o -o test在实际编程中,我们都会让源文件直接生成可执行文件,以下面简单C程序为例:
#include <stdio.h>
int main()
{
printf("hello, luckfox\n");
return 0;
}编译并运行:
gcc test.c -o test
./test运行结果:
linaro@linaro-alip:~$ ./test
hello, luckfox
linaro@linaro-alip:~$
3.1.3 交叉编译
如果我们希望编译器运行在x86架构平台上,然后编译生成ARM架构的可执行程序,这种编译器和目标程序运行在不同架构的编译过程,被称为交叉编译。
安装ARM-GCC编译器:
#在主机上执行如下命令
sudo apt install gcc-arm-linux-gnueabihf安装完成后编译生成ARM架构的可执行程序:
arm-linux-gnueabihf-gcc test.c -o test查看可执行程序具体属于哪个架构:
file testlinaro@linaro-alip:~$ file test
test: ELF 64-bit LSB pie executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, for GNU/Linux 3.7.0, BuildID[sha1]=c4bfa4bceebabc10960c9689759cad948782e91c, not stripped
linaro@linaro-alip:~$
3.2 g++ 编译器
g++ 是GNU组织退出的 C++ 编译器。它编译程序的内部过程和 gcc 的一样,使用 g++ 编译C++ 程序会自动链接到 C++ 的标准库,不需要自己手工指定。
4. Makefile 基础
4.1 make工具
- make工具是一个用于自动化构建软件的工具,它通过读取 Makefile 文件中的规则,自动化执行编译、链接和打包等构建过程。
- make工具解决了软件开发过程中手动编译、链接和打包程序的繁琐和复杂性,特别是在大型项目中,由于源代码量大、文件依赖关系复杂等因素,手动编译变得非常困难和容易出错。调用make工具也是十分简单,直接在终端输入 make 命令即可。
4.2 Makefile
Makefile 是一个用于自动化编译程序的文件,包含了一系列规则,指示了如何编译程序,如何生成可执行文件,以及如何清理编译生成的临时文件等。makefile 的命令必须是 makefile 或者 Makefile。
4.3 Makefile 的显式规则
在 Makefile 中,#代表着注释,这个是不会被编译进去的,指令前必须打一个Tab键,按四下空格会报错。Makefile 的基本语法是:
目标:依赖
(tab)命令如果想要编译当前文件夹中有test.c文件,Makefile内容应为:
all:
gcc test.c -o test上述的程序也可以写成:
all:test.o
gcc test.o -o test
test.o:test.c
gcc -c test.c因为 all 依赖 test.o 文件,所以要先执行 gcc -c test.c 得到 test.o 文件,然后才可以执行gcc test.c -o test。所以输入 make 命令后执行顺序如下:
pi@raspberrypi:~/test $ make
gcc -c test.c
gcc test.o -o test
pi@raspberrypi:~/test $在 Makefile 文件中,.PHONY 是一个特殊的目标,用于指定伪目标(即不对应实际文件)列表。这些目标通常表示需要执行的命令或操作,而不是生成文件。使用 .PHONY 目标可以告诉 make 工具,在执行伪目标时不需要检查对应的文件是否存在,如果没有使用 .PHONY,在 Makefile 文件中定义的目标名称与文件名称重名时,make 工具可能会出现错误。例如,如果我们想要使用make clean 清除上次的make命令所产生的object文件(后缀为“.o”的文件)及可执行文件,下面是一个 Makefile 示例,其中定义了 .PHONY 目标和伪目标:
all:test.o
gcc test.o -o test
test .o:test.c
gcc -c test.c
PHONY:clean
clean:
rm -rf *.o test
4.4 自定义变量
- 在 Makefile 中,变量是非常重要的概念。变量可以在 Makefile 中许多地方使用,比如目标、依赖或者命令中。变量的赋值可以使用以下几种方式:
- =:直接赋值。变量的值会在使用时递归展开。例如:VAR = value。
- ?=:如果变量未定义,则为其赋值。例如:VAR ?= value。
- :=:简单赋值。变量的值会在赋值时立即展开。例如:VAR := value。
- +=:追加值。将一个值追加到变量的值的末尾。例如:VAR += value。
- 变量的使用是通过 $() 来完成变量的引用。例如:$(VAR)。在使用变量时,Makefile 会自动将变量的值展开并替换掉 $() 中的变量名。
4.5 预定义变量
预定义变量其实就是系统内已经定义好的变量,变量名已经确定了,直接使用的话,使用的是默认值,你也可以重新赋值。下面列出一些常见的:
变量名 含义 CC C编译器的名称,默认值为cc,即默认使用gcc编译器 RM 文件删除程序的名称,默认值为rm -f CFLAGS C编译器(gcc)的选项,无默认值,如-Wall、-g、-o CPP C预编译器的名称,默认值为$(CC) –E CPPFLAGS C预编译的选项,无默认值 CXXFLAGS C++编译器(g++)的选项,无默认值
4.6 自动化变量
自动变量有具体的含义,不可被修改。下面是一些常见自动变量:
动变量的引用 含义 $< 第一个依赖文件的名称 $@ 目标文件的完整名称 $^ 所有不重复的目标依赖文件,以空格分开 $? 代表示比目标还要新的依赖文件列表,以空格分隔 例如,在工程中有 luckfox.c、luckfox.h 、main.c 和 Makefile 四个文件,Makefile 文件内容如下:
luckfox.h 示例程序:
#ifndef _LUCKFOX_H
#define _LUCKFOX_H
void luckfox(void);
#endifluckfox.c 示例程序:
#include <stdio.h>
#include "luckfox.h"
void luckfox(void)
{
printf("hello, luckfox\n");
}main.c 示例程序:
#include <stdio.h>
#include "luckfox.h"
int main()
{
luckfox();
}Makefile 文件内容如下:
luckfox:luckfox.o main.o
gcc luckfox.o main.o -o luckfox
luckfox.o:luckfox.c
gcc -c luckfox.c -o luckfox.o
main.o:main.c
gcc -c main.c -o main.o
.PHONY:clean
clean:
rm -rf *.o luckfox
使用自动化变量来简化 Makefile 文件可以减少编写复杂度,尤其在项目文件较多的情况下:
var:=luckfox.o main.o
luckfox:$(var)
gcc $^ -o luckfox
%.o:%.c
gcc -c $< -o $@
.PHONY:clean
clean:
rm -rf *.o luckfoxvar:变量表示依赖文件 luckfox.o 和 main.o;
$^:表示所有的依赖文件 luckfox.o 和main.o,等同于$(var);
%.o:表示里面所有的.o文件,即luckfox.o和main.o;
%.c:表示里面所有的.c文件,即luckfox.c和main.c;
$<:表示luckfox.c和main.c;
$@:表示由luckfox.c和main.c生成的目标文件luckfox.o和main.o。编译单独的 C 语言源程序并不需要写出命令,因为 make 可以把它推断出来,例如 make 可以自动使用 ‘cc -c main.c -o main.o’ 命令把 ‘main.c’ 编译 ‘main.o’,上述程序可以写为:
var:=luckfox.o main.o
luckfox:$(var)
cc $^ -o luckfox
%.o:%.c
cc -c $< -o $@
.PHONY:clean
clean:
rm -rf *.o luckfox